


1.下载模型
建议到modelscope下载:https://www.modelscope.cn/models/deepseek-ai/Janus-Pro-1B
建议用命令行下载,网站写的很清楚,这里不多说了
2.Git克隆+Conda创建
我这里使用miniconda3创建Python 3.10环境
通过Git克隆Janus的官方仓库:https://github.com/deepseek-ai/Janus
3.安装依赖
运行命令:
pip install -e .[gradio]4.精度问题
如果此时直接运行的话,会遇到报错:
RuntimeError: "slow_conv2d_cpu" not implemented for 'Half'这是因为Pytorch的CPU版本不支持float16精度导致
这里我们需要更改精度为float32
更改demo/app_januspro.py文件中的两处float16为float32
更改前:


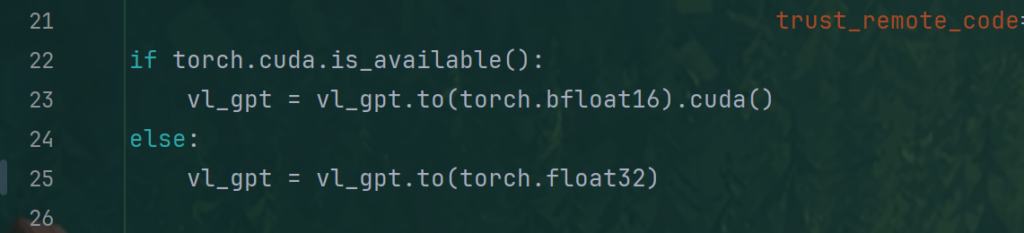
更改后:

5.设置模型
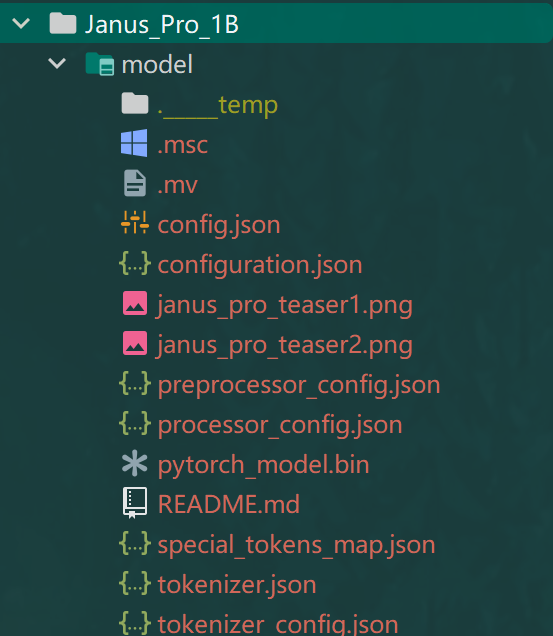
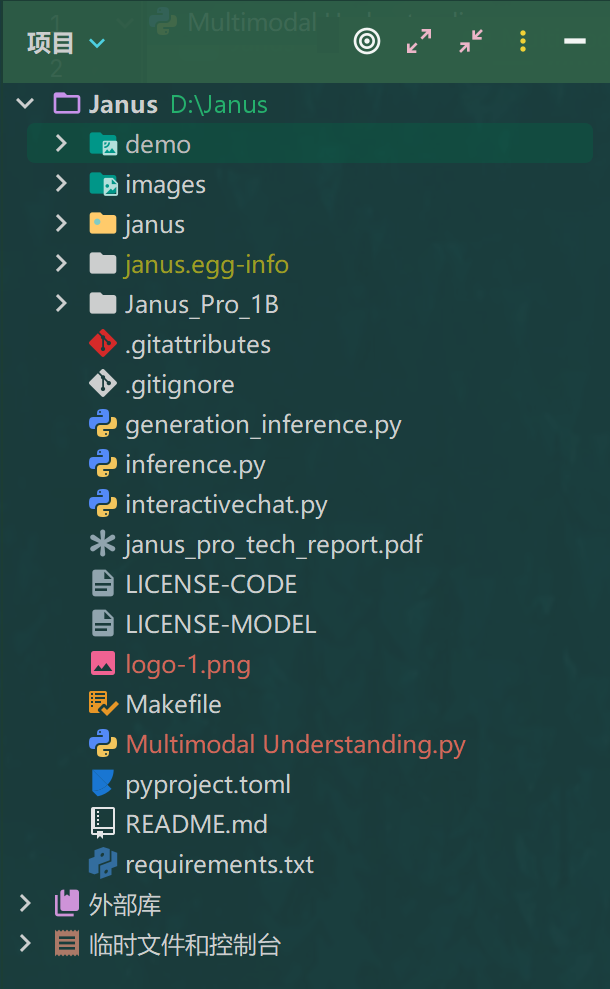
目录结构:
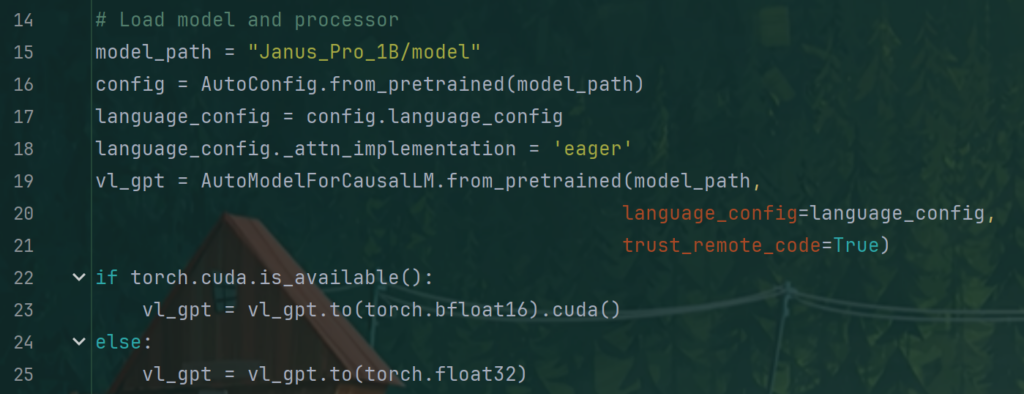
更改demo/app_januspro.py文件的第15行
将模型改成model文件夹的相对路径,如下:
6.运行
执行命令:
python demo/app_januspro.py请确保命令行在根目录中运行,不然会找不到model
效果:(CPU计算,速度很慢,通常都在100s以上)
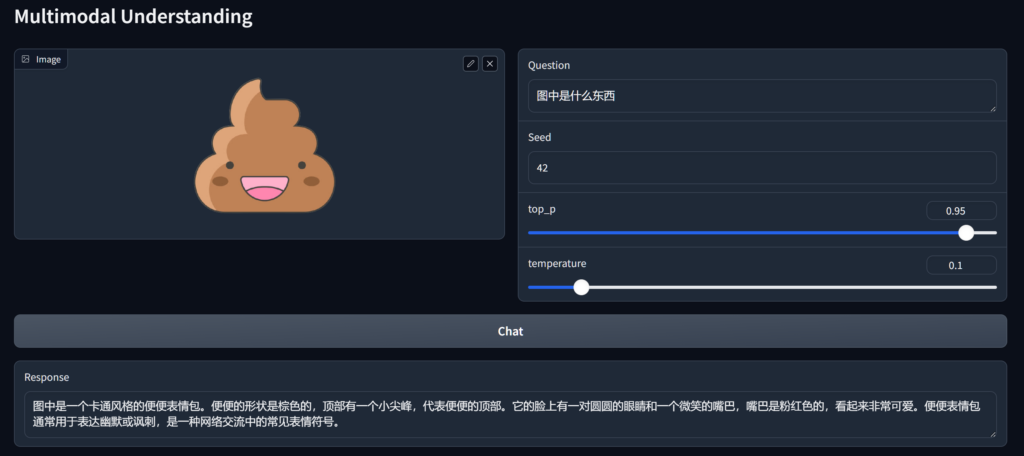
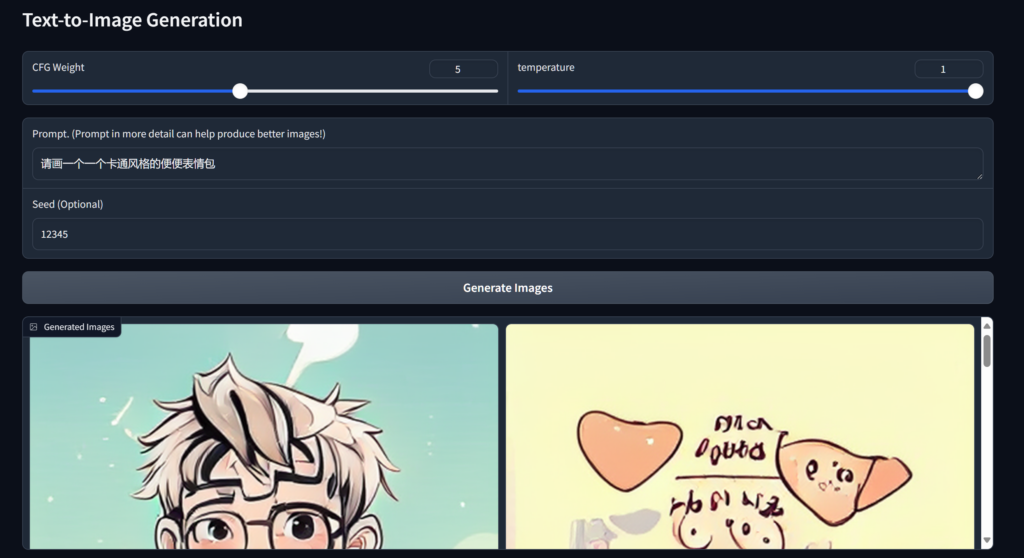
(很显然,对中文的理解并不好)
实测,32G内存几乎吃满
7.进击的巨人
官方给的两个推理示例基本没法用,我修改了一个,另一个差不多这么改改
Multimodal Understanding
import torch
from transformers import AutoModelForCausalLM
from janus.models import MultiModalityCausalLM, VLChatProcessor
from janus.utils.io import load_pil_images
# specify the path to the model
model_path = "Janus_Pro_1B/model"
vl_chat_processor: VLChatProcessor = VLChatProcessor.from_pretrained(model_path)
tokenizer = vl_chat_processor.tokenizer
vl_gpt: MultiModalityCausalLM = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True
)
vl_gpt = vl_gpt.to(torch.float32).cpu().eval()
conversation = [
{
"role": "<|User|>",
"content": f"<image_placeholder>\n图片中是什么?",
"images": ["logo-1.png"]
},
{"role": "<|Assistant|>", "content": ""},
]
# load images and prepare for inputs
pil_images = load_pil_images(conversation)
prepare_inputs = vl_chat_processor(
conversations=conversation, images=pil_images, force_batchify=True
).to(vl_gpt.device,dtype=torch.float32)
# # run image encoder to get the image embeddings
inputs_embeds = vl_gpt.prepare_inputs_embeds(**prepare_inputs)
# # run the model to get the response
outputs = vl_gpt.language_model.generate(
inputs_embeds=inputs_embeds,
attention_mask=prepare_inputs.attention_mask,
pad_token_id=tokenizer.eos_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=512,
do_sample=False,
use_cache=True,
)
answer = tokenizer.decode(outputs[0].cpu().tolist(), skip_special_tokens=True)
print(f"{prepare_inputs['sft_format'][0]}", answer)请注意目录结构:
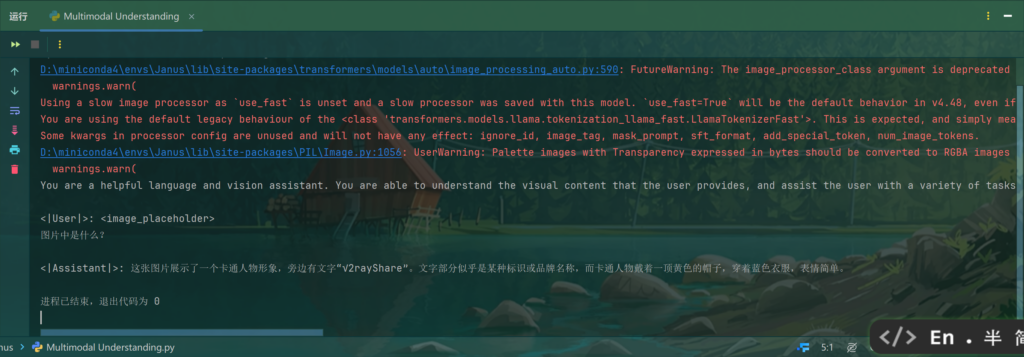
运行效果:
The End.
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END









暂无评论内容