


1.下载模型
请前往modelscope下载(虽然快不到哪去):
https://www.modelscope.cn/models/Efficient-Large-Model/Sana_600M_1024px_diffusers
所有带有.fp16的模型文件都可以不下载,CPU用不上
请留足硬盘空间,模型预计占用17GB(算上.fp16的模型权重)
2.安装依赖
运行命令:
pip install git+https://github.com/huggingface/diffusers这个有大坑,如果遇到报错:
error: subprocess-exited-with-error建议尝试:
pip install setuptools==69.0.0(如果不行就真没救了)
3.运行代码
无RAG:
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPipeline
pipe = SanaPipeline.from_pretrained(
"Efficient-Large-ModelSana_600M_1024px_diffusers\model",
#variant="fp16",
torch_dtype=torch.float32,
)
pipe.to("cpu")
pipe.vae.to(torch.float32)
pipe.text_encoder.to(torch.float32)
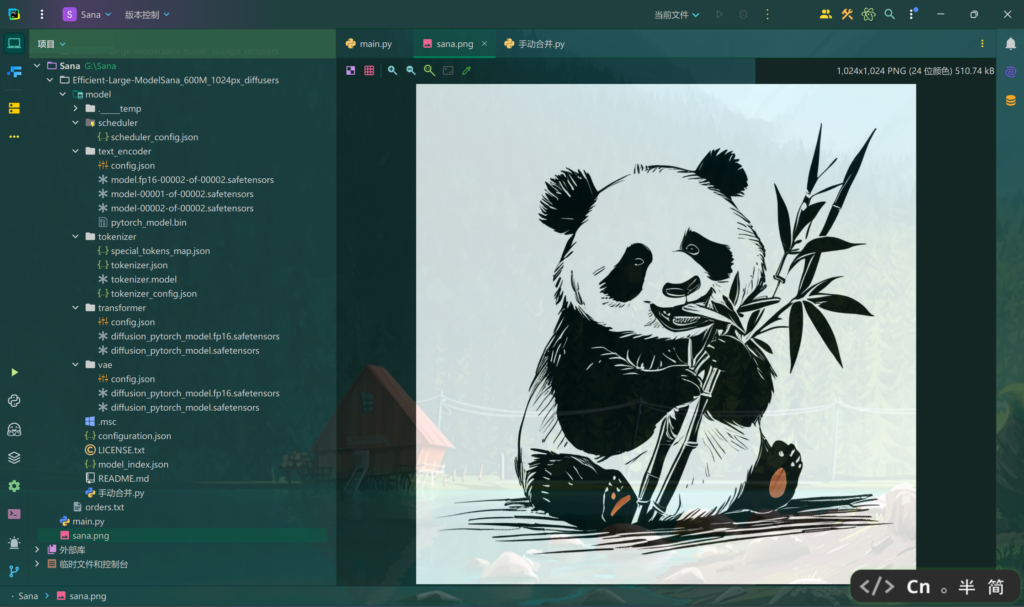
prompt = 'A cute 🐼 eating 🎋, ink drawing style'
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=4.5,
num_inference_steps=20,
generator=torch.Generator(device="cpu").manual_seed(42),
)[0]
image[0].save("sana.png")有RAG:
# run `pip install git+https://github.com/huggingface/diffusers` before use Sana in diffusers
import torch
from diffusers import SanaPAGPipeline
pipe = SanaPAGPipeline.from_pretrained(
"Efficient-Large-ModelSana_600M_1024px_diffusers\model",
# variant="fp16",
torch_dtype=torch.float32,
pag_applied_layers="transformer_blocks.8",
)
pipe.to("cpu")
pipe.text_encoder.to(torch.float32)
pipe.vae.to(torch.float32)
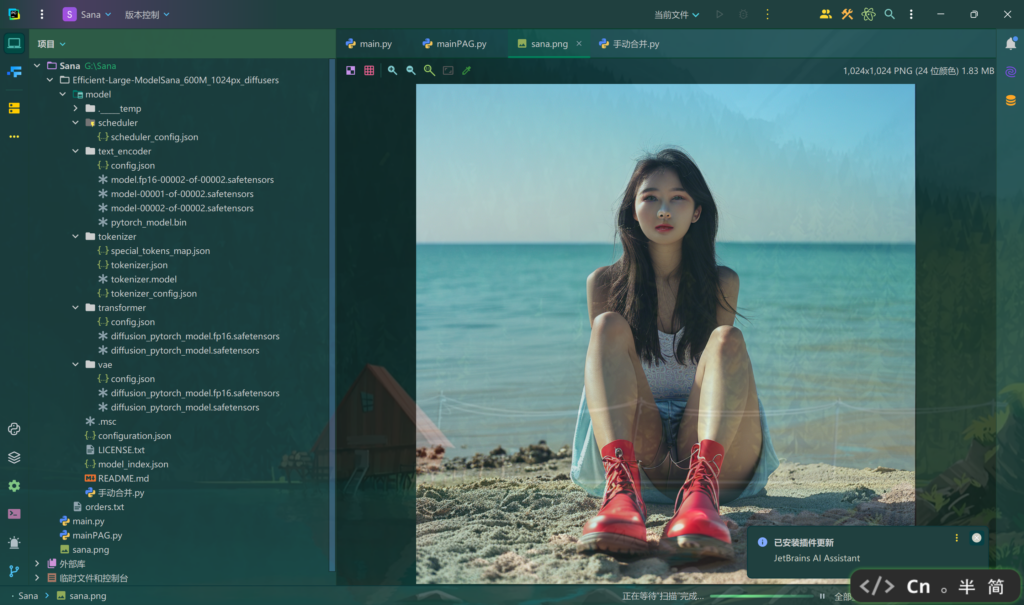
prompt = 'A beautiful girl'
image = pipe(
prompt=prompt,
height=1024,
width=1024,
guidance_scale=5.0,
pag_scale=2.0,
num_inference_steps=20,
generator=torch.Generator(device="cpu").manual_seed(42),
)[0]
image[0].save('sana.png')"Efficient-Large-ModelSana_600M_1024px_diffusers\model"是模型目录的相对路径
文件结构如下:

4.大坑
因为某些不可抗力因素,diffusers大概率不会自动合并text_encoder下的两个被切分过的模型,多半是版本问题,但是目前好像没有办法解决版本问题:(
所以我们只能手动合并(其他模型同样可用):
from safetensors import safe_open
import torch
state_dict = {}
for shard in ["model-00001-of-00002.safetensors", "model-00002-of-00002.safetensors"]:
with safe_open(f"text_encoder/{shard}", framework="pt") as f:
for key in f.keys():
state_dict[key] = f.get_tensor(key)
# 保存为单个文件(临时解决)
torch.save(state_dict, "text_encoder/pytorch_model.bin") # 注意:这会占用双倍磁盘空间参考上图的文件结构
5.运行
虽然效果依然不咋滴,但可以吊打Janus Pro了
(16G内存应该可以试一试)(支持中文提示词)
The End
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END









暂无评论内容